
الفهرسة الدلالية الكامنة (LSI) هي طريقة لفهرسة المعلومات واسترجاعها تستخدم لتحديد الأنماط في العلاقات بين المصطلحات والمفاهيم.
باستخدام LSI ، يتم استخدام تقنية رياضية للبحث لغويا المصطلحات ذات الصلة في مجموعة من النص (أ فهرس) حيث قد تكون هذه العلاقات مخفية (أو كامن).
وفي هذا السياق ، يبدو أنه مهم جدًا لتحسين محركات البحث.
على اليمين؟
بعد كل شيء ، يعد Google فهرسًا ضخمًا للمعلومات ، ونسمع كل أنواع الأشياء عنه البحث الدلالي و ال أهمية الصلة في خوارزمية ترتيب البحث.
إذا كنت قد سمعت شائعات حول الفهرسة الدلالية الكامنة في تحسين محركات البحث أو تم نصحك باستخدام كلمات LSI الأساسية ، فأنت لست وحدك.
ولكن هل سيساعدك LSI بالفعل على تحسين تصنيفات البحث الخاصة بك؟ سوف نلقي نظرة.
التأكيد: الفهرسة الدلالية الكامنة كعامل ترتيب
العبارة بسيطة: تحسين محتوى الويب باستخدام كلمات LSI الأساسية يساعد Google على فهمه بشكل أفضل وستحصل على تصنيفات أعلى.
يعرّف Backlinko الكلمات الرئيسية لـ LSI بهذه الطريقة:
“الكلمات الرئيسية لـ LSI (الفهرسة الدلالية الكامنة) هي مصطلحات مرتبطة بالمفاهيم تستخدمها محركات البحث لفهم محتوى صفحة الويب بعمق.”
باستخدام المصطلحات المتعلقة بالسياق ، يمكنك تعميق فهم Google للمحتوى الخاص بك. أو هكذا تقول القصة.
يستمر هذا المورد في تقديم بعض الحجج المقنعة جدًا للكلمات الرئيسية LSI:
- “تعتمد Google على الكلمات الرئيسية LSI لفهم المحتوىر في مثل هذا المستوى العميق.
- “LSI الكلمات الرئيسية ليست مرادفات. بدلاً من ذلك ، هذه مصطلحات وثيقة الصلة بكلمتك الرئيسية المستهدفة. »
- “لا تعرض Google المصطلحات المكتوبة بخط عريض فقط والتي تتطابق تمامًا ما الذي بحثت عنه للتو (في نتائج البحث). لديهم أيضًا كلمات وعبارات بالخط العريض متشابهة. وغني عن القول ، هذه هي كلمات LSI الأساسية التي تريد رشها في المحتوى الخاص بك.
هل تساعد ممارسة “رش” المصطلحات المرتبطة ارتباطًا وثيقًا بكلمتك الرئيسية المستهدفة في تحسين ترتيبك من خلال LSI؟
دليل إل إس آي (LSI) كعامل تصنيف
يتم تحديد الملاءمة كواحد من خمسة عوامل رئيسية تساعد Google في تحديد النتيجة الأفضل لاستعلام معين.
كما توضح Google ، فإن هذا هو كيف يعمل البحث المورد:
“لإرجاع النتائج ذات الصلة لاستعلامك ، نحتاج أولاً إلى تحديد المعلومات التي تبحث عنها ، والغرض من استعلامك.”
بمجرد تحديد النية:
“… تحلل الخوارزميات محتوى صفحات الويب لتحديد ما إذا كانت الصفحة تحتوي على معلومات قد تكون ذات صلة بما تبحث عنه.”
يمضي Google في شرح أن “الإشارة الأساسية” ذات الصلة هي أن الكلمات الرئيسية المستخدمة في استعلام البحث تظهر على الصفحة. هذا منطقي – إذا كنت لا تستخدم الكلمات الرئيسية التي يبحث عنها الباحث ، فكيف يمكن لـ Google أن يخبرك بأنك أفضل إجابة؟
الآن ، هذا هو المكان الذي يعتقد البعض أن LSI يأتي فيه.
إذا كان استخدام الكلمات الرئيسية هو إشارة إلى الملاءمة ، والاستخدام فقط الكلمات الرئيسية الصحيحة يجب أن تكون إشارة أقوى.
هناك أدوات مصممة خصيصًا لمساعدتك في العثور على كلمات LSI هذه ، ويوصي مؤيدو هذا التكتيك باستخدام جميع أنواع أساليب البحث عن الكلمات الرئيسية الأخرى لتحديدها أيضًا.
الدليل ضد إل إس آي (LSI) كعامل تصنيف
كان جون مولر من Google اضحة وضوح الشمس على هذا واحد:
“… ليس لدينا مفهوم للكلمات الرئيسية LSI. لذا فهو شيء يمكنك تجاهله تمامًا.
هناك شكوك صحية في مُحسّنات محرّكات البحث بأن Google يمكنها قول أشياء لتضليلنا من أجل حماية سلامة الخوارزمية. لذلك دعونا نحفر هنا.
أولاً ، من المهم فهم ماهية إل. إس. آي. LSI ومن أين أتت.
ظهرت البنية الدلالية الكامنة كمنهجية لاسترداد الكائنات النصية من الملفات المخزنة في نظام الكمبيوتر في أواخر الثمانينيات.وبالتالي ، فهي مثال على أحد المفاهيم المبكرة لاسترجاع المعلومات (IR) المتاحة للمبرمجين.
مع تحسن سعة تخزين الكمبيوتر وزيادة حجم مجموعات البيانات المتاحة إلكترونيًا ، أصبح من الصعب تحديد ما كان يبحث عنه المرء بالضبط في تلك المجموعة.
وصف الباحثون المشكلة التي كانوا يحاولون حلها بطريقة ما طلب البراءة تم تقديمه في 15 سبتمبر 1988:
“لا تزال معظم الأنظمة تتطلب من المستخدم أو مزود المعلومات تحديد العلاقات والروابط الصريحة بين كائنات البيانات أو الكائنات النصية ، مما يجعل الأنظمة مرهقة لاستخدامها أو تطبيقها على ملفات البيانات. معلومات الكمبيوتر الضخمة وغير المتجانسة التي قد يكون محتواها غير مألوف للمستخدم. “
تم استخدام مطابقة الكلمات الرئيسية في IR في ذلك الوقت ، ولكن قيودها كانت واضحة قبل وقت طويل من ظهور Google.
في كثير من الأحيان ، الكلمات التي استخدمها الشخص للبحث عن المعلومات التي كان يبحث عنها لا تتطابق تمامًا مع الكلمات المستخدمة في المعلومات المفهرسة.
هناك سببان لهذا :
- مرادف: تنوع الكلمات المستخدمة لوصف كائن واحد أو فكرة واحدة يؤدي إلى فقدان النتائج ذات الصلة.
- تعدد المعاني: معاني مختلفة لنفس الكلمة تؤدي إلى استرجاع نتائج غير ذات صلة.
لا تزال هذه مشكلات حتى اليوم ، ويمكنك أن تتخيل مدى صعوبة Google.
ومع ذلك ، فإن المنهجيات والتقنيات التي تستخدمها Google لحل الملاءمة قد تطورت منذ فترة طويلة من LSI.
ما فعله LSI هو إنشاء “مساحة دلالية” تلقائيًا لاسترجاع المعلومات.
كما توضح براءة الاختراع ، تعامل LSI مع عدم موثوقية بيانات الارتباط هذه كمشكلة إحصائية.
دون الخوض في الكثير من التفاصيل ، اعتقد هؤلاء الباحثون بشكل أساسي أن هناك بعض البنية الدلالية الكامنة الكامنة التي يمكنهم فصلها عن بيانات استخدام الكلمات.
سيكشف هذا المعنى الكامن ويسمح للنظام بإرجاع المزيد من النتائج ذات الصلة – و وحده النتائج الأكثر صلة ، حتى لو لم تكن هناك مطابقة تامة للكلمات الرئيسية.
إليك ما تبدو عليه عملية LSI هذه في الواقع:
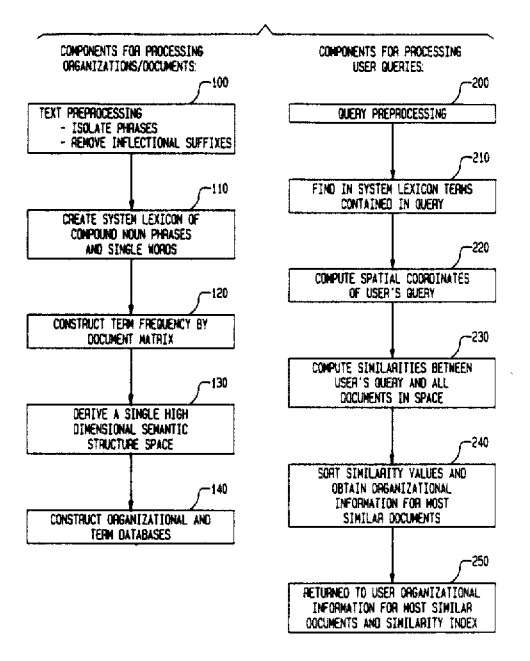 صورة تم إنشاؤها بواسطة المؤلف ، يناير 2022
صورة تم إنشاؤها بواسطة المؤلف ، يناير 2022وإليك أهم شيء يجب ملاحظته حول الرسم التوضيحي أعلاه لمنهجية طلب البراءة هذه: هناك عمليتان متميزتان تحدثان.
أولاً ، تخضع المجموعة أو الفهرس لتحليل دلالي كامن.
ثانيًا ، يتم تحليل الاستعلام ثم يتم البحث عن أوجه التشابه في الفهرس الذي تمت معالجته بالفعل.
وهنا تكمن المشكلة الأساسية في LSI كإشارة ترتيب بحث Google.
فهرس Google هو جسيم الى مئات المليارات صفحات ، وتستمر في النمو.
في كل مرة يقوم المستخدم بإدخال استعلام ، تقوم Google بفرز فهرسها في جزء من الثانية للعثور على أفضل إجابة.
يتطلب استخدام المنهجية المذكورة أعلاه في الخوارزمية من Google:
- أعد إنشاء هذه المساحة الدلالية باستخدام LSA على فهرسها بالكامل.
- تحليل المعنى الدلالي من الطلب.
- ابحث عن جميع أوجه التشابه بين المعنى الدلالي للاستعلام والمستندات الموجودة في المساحة الدلالية التي تم إنشاؤها من تحليل الفهرس الكامل.
- الفرز والتصنيف هذه النتائج.
إنه تبسيط فادح ، لكن المهم هو أنه ليس عملية تطورية.
سيكون هذا مفيدًا جدًا للمجموعات الصغيرة من المعلومات. كان مفيدًا في عرض التقارير ذات الصلة في أرشيف التوثيق التقني المحوسب للشركة ، على سبيل المثال.
يوضح طلب براءة الاختراع تشغيل LSI باستخدام مجموعة من تسعة مستندات. هذا ما تم تصميمه للقيام به. LSI بدائية من حيث استرداد المعلومات المحوسبة.
الفهرسة الدلالية الكامنة كعامل تصنيف: حكمنا

في حين أن المبادئ الأساسية للقضاء على التشويش من خلال تحديد الملاءمة الدلالية قد أطلعت بالتأكيد على التطورات في ترتيب البحث منذ أن تم تسجيل براءة اختراع LSA / LSI ، فإن LSI نفسها ليس لها تطبيق مفيد في تحسين محركات البحث اليوم.
لم يتم استبعاد ذلك تمامًا ، ولكن لا يوجد دليل على أن Google قد استخدمت LSI على الإطلاق لتصنيف النتائج. وبالتأكيد لا تستخدم Google الكلمات الرئيسية LSI أو LSI اليوم لترتيب نتائج البحث.
أولئك الذين يوصون باستخدام كلمات LSI الأساسية يتمسكون بمفهوم لا يفهمونه تمامًا في محاولة لشرح سبب ارتباط الكلمات (أو عدم ارتباطها) في مُحسّنات محرّكات البحث.
تعتبر الملاءمة والنية من الاعتبارات الأساسية في خوارزمية ترتيب بحث Google.
هذان هما من أكبر الأسئلة التي يحاولون الإجابة عليها للعثور على أفضل إجابة لأي استفسار.
تظل المرادفات وتعدد المعاني من القضايا الرئيسية.
دلالات – أي فهمنا للمعاني المختلفة للكلمات وعلاقتها – هو المفتاح لإنتاج نتائج بحث أكثر صلة.
لكن LSI ليس لها علاقة به.
الصورة المميزة: باولو بوبيتا / مجلة محرك البحث
#هل #هو #عامل #ترتيب #جوجل
المصدر
