
ملحوظة المحرر: مع اقتراب عام 2021 من نهايته ، نحتفل بالعد التنازلي لـ 12 يومًا من عيد الميلاد بمقالات الخبراء الأكثر شعبية وفائدة في مجلة محرك البحث هذا العام.
تم تنسيق هذه المجموعة من قبل فريق التحرير لدينا بناءً على الأداء والفائدة والجودة والقيمة التي تم إنشاؤها لك ، لقرائنا ، لكل مقال.
كل يوم حتى 24 كانون الأول (ديسمبر) ، سنقوم بإعادة نشر أحد أفضل أعمدة العام ، بدءًا من الرقم 12 والعودة إلى رقم 1. يبدأ العد التنازلي اليوم بعمودنا رقم 5 ، والذي تم نشره في الأصل في 4 أغسطس. ، 2021.
هذا الدليل الإرشادي من Andrea Atzori يعلم القراء كيفية استخدام جداول بيانات Google لكشط الويب وبناء الحملات ، دون الحاجة إلى خبرة في الترميز.
يتمتع!
لقد مررنا جميعًا بموقف اضطررنا فيه إلى سحب البيانات من موقع ويب في مرحلة ما.
عند العمل في حساب أو حملة جديدة ، قد لا تتوفر لديك البيانات أو المعلومات لإنشاء الإعلانات ، على سبيل المثال.
دعاية
أكمل القراءة أدناه
في عالم مثالي ، سنكون قد تلقينا كل المحتوى ذي الصلة والصفحات المقصودة والمعلومات التي نحتاجها ، بتنسيق سهل الاستيراد ، مثل ملف CSV أو جدول بيانات Excel أو ورقة Google. (أو على الأقل ، بشرط أن نحتاج إلى بيانات مجدولة يمكن استيرادها بأي من التنسيقات المذكورة أعلاه.)
لكن هذا ليس هو الحال دائمًا.
أولئك الذين ليس لديهم أدوات تجريف الويب – أو معرفة الترميز لاستخدام شيء مثل Python للمساعدة في المهمة – ربما اضطروا إلى اللجوء إلى العمل الشاق المتمثل في النسخ واللصق يدويًا ، وربما مئات أو آلاف. من الإدخالات.
في وظيفة حديثة ، تمت دعوة فريقي إلى:
- اذهب إلى موقع العميل.
- قم بتنزيل أكثر من 150 منتجًا جديدًا موزعة على 15 صفحة مختلفة.
- انسخ والصق اسم المنتج وعنوان URL للصفحة المقصودة لكل منتج في جدول بيانات.
يمكنك الآن تخيل المدة التي كانت ستستغرقها المهمة إذا قمنا بذلك بالضبط وقمنا بتنفيذ المهمة يدويًا.
دعاية
أكمل القراءة أدناه
لا يقتصر الأمر على مضيعة للوقت فحسب ، ولكن مع مرور شخص ما يدويًا بالعديد من العناصر والصفحات والاضطرار إلى نسخ منتج البيانات ولصقه فعليًا حسب المنتج ، فإن فرص ارتكاب خطأ أو خطأين عالية جدًا.
سيستغرق الأمر وقتًا أطول لمراجعة المستند والتأكد من خلوه من الأخطاء.
يجب أن تكون هناك طريقة أفضل.
بشرى سارة: هناك! اسمحوا لي أن أريكم كيف فعلنا ذلك.
ما هو IMPORTXML؟
أدخل جداول بيانات Google. أود أن تتعرف على وظيفة IMPORTXML.
بحسب جوجل صفحة الدعم، IMPORTXML “يستورد البيانات من أي نوع من البيانات المنظمة ، بما في ذلك خلاصات XML و HTML و CSV و TSV و RSS و ATOM XML.”
بشكل أساسي ، تعد IMPORTXML ميزة تتيح لك استرداد البيانات المنظمة من صفحات الويب – لا تتطلب معرفة الترميز.
على سبيل المثال ، من السهل والسريع استخراج البيانات مثل عناوين الصفحات أو الأوصاف أو الروابط ، ولكن أيضًا المعلومات الأكثر تعقيدًا.
كيف يمكن لـ IMPORTXML المساعدة في كشط العناصر من صفحة ويب؟
الوظيفة نفسها بسيطة للغاية وتتطلب قيمتين فقط:
- عنوان URL لصفحة الويب التي ننوي استخراج المعلومات منها أو استردادها.
- و ال XPath للعنصر الذي تحتوي عليه البيانات.
XPath يعني لغة مسار XML ويمكن استخدامها لتصفح عناصر وسمات وثيقة XML.
على سبيل المثال ، لاستخراج عنوان الصفحة من https://en.wikipedia.org/wiki/Moon_landing ، سنستخدم:
= IMPORTXML (“https://en.wikipedia.org/wiki/Moon_landing”، “// title”)
سيعيد هذا القيمة: الهبوط على القمر – ويكيبيديا.
أو ، إذا كنا نبحث عن وصف الصفحة ، فجرّب ما يلي:
= IMPORTXML (“https://www.searchenginejournal.com/”،”//meta[@name=’description’]/@محتويات”)
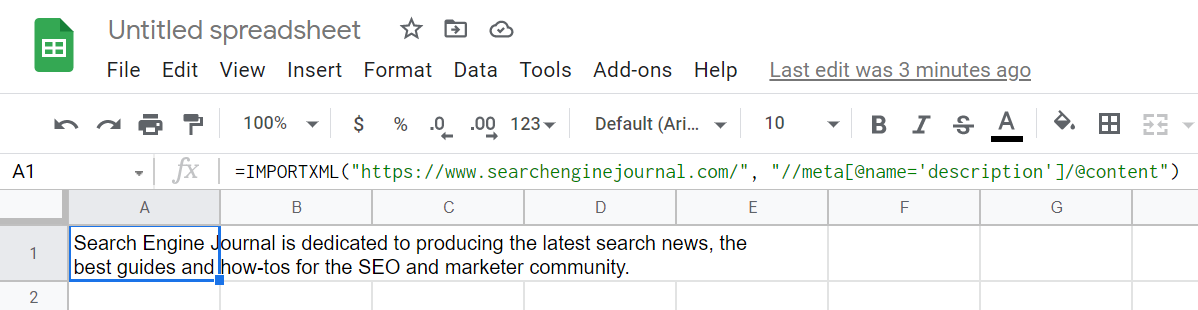
فيما يلي قائمة مختصرة لبعض استعلامات XPath الأكثر شيوعًا وفائدة:
دعاية
أكمل القراءة أدناه
- عنوان الصفحة: // العنوان
- وصف ميتا للصفحة: // ميتا[@name=’description’]/@محتويات
- الصفحة H1: // h1
- روابط الصفحات: // @ href
انظر IMPORTXML في العمل
منذ اكتشاف IMPORTXML في جداول بيانات Google ، أصبح حقًا أحد أسلحتنا السرية في أتمتة العديد من مهامنا اليومية ، من إنشاء الحملات والإعلانات إلى البحث عن المحتوى والمزيد. مرة أخرى.
بالإضافة إلى ذلك ، يمكن استخدام الوظيفة المدمجة مع الصيغ والوظائف الإضافية الأخرى للمهام الأكثر تقدمًا التي تتطلب حلولًا وتطويرًا متطورًا ، مثل الأدوات المضمنة في Python.
لكن في هذه الحالة ، سننظر في IMPORTXML في أبسط أشكاله: استخراج البيانات من صفحة ويب.
دعونا نرى مثالا عمليا.
تخيل أن يُطلب منك إنشاء حملة لمجلة محرك البحث.
يريدون منا نشر آخر 30 مقالة منشورة في قسم PPC بالموقع.
دعاية
أكمل القراءة أدناه
قد تقول إنها مهمة بسيطة إلى حد ما.
لسوء الحظ ، لا يستطيع المحررون إرسال البيانات إلينا وقد طلبوا التفضل بالرجوع إلى الموقع للبحث في المعلومات اللازمة لإعداد الحملة.
كما ذكرنا في بداية مقالتنا ، تتمثل إحدى طرق القيام بذلك في فتح نافذتين للمتصفح – واحدة مع موقع الويب والأخرى باستخدام جداول بيانات Google أو Excel. سنبدأ بعد ذلك في نسخ المعلومات ولصقها ، مقالة بمقال ورابط عن طريق رابط.
ولكن باستخدام IMPORTXML في “جداول بيانات Google” ، يمكننا تحقيق نفس النتيجة مع القليل من المخاطرة بارتكاب الأخطاء أو بدون مخاطر ، في جزء بسيط من الوقت.
إليك الطريقة.
الخطوة 1: ابدأ بورقة Google الجديدة
أولاً ، نفتح مستندًا جديدًا فارغًا في جداول بيانات Google:
الخطوة 2: أضف المحتوى الذي تريد خدشه
أضف عنوان URL للصفحة (أو الصفحات) التي نريد استخراج المعلومات منها.
دعاية
أكمل القراءة أدناه
في حالتنا ، نبدأ بـ https://www.searchenginejournal.com/category/pay-per-click/:
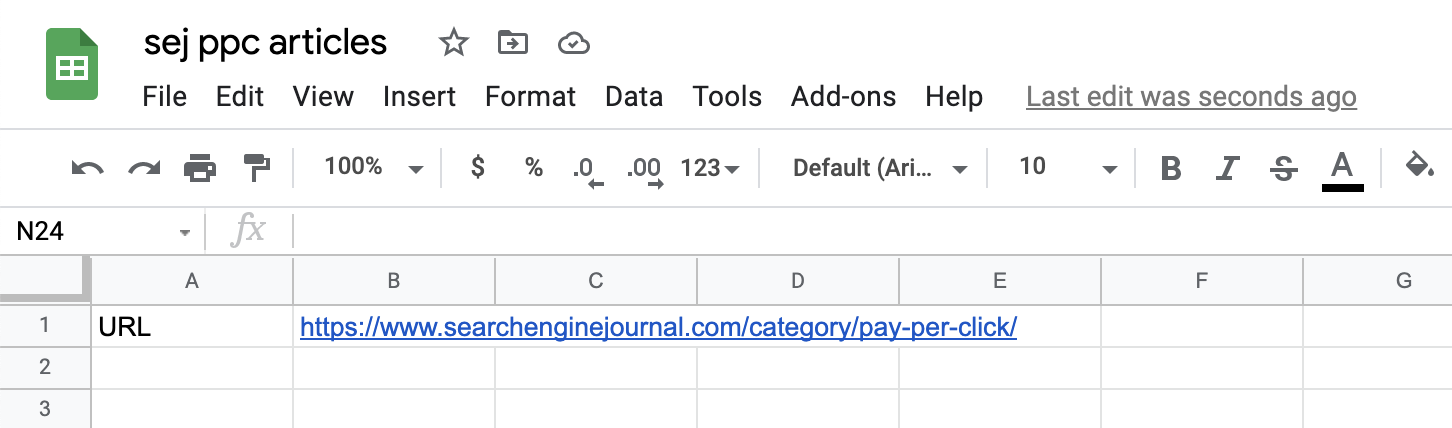 لقطة شاشة من جداول بيانات Google ، يوليو 2021
لقطة شاشة من جداول بيانات Google ، يوليو 2021الخطوة 3: ابحث عن ملف XPath
نجد XPath للعنصر الذي نريد استيراد محتواه إلى جدول بياناتنا.
في مثالنا ، لنبدأ بعناوين آخر 30 مقالة.
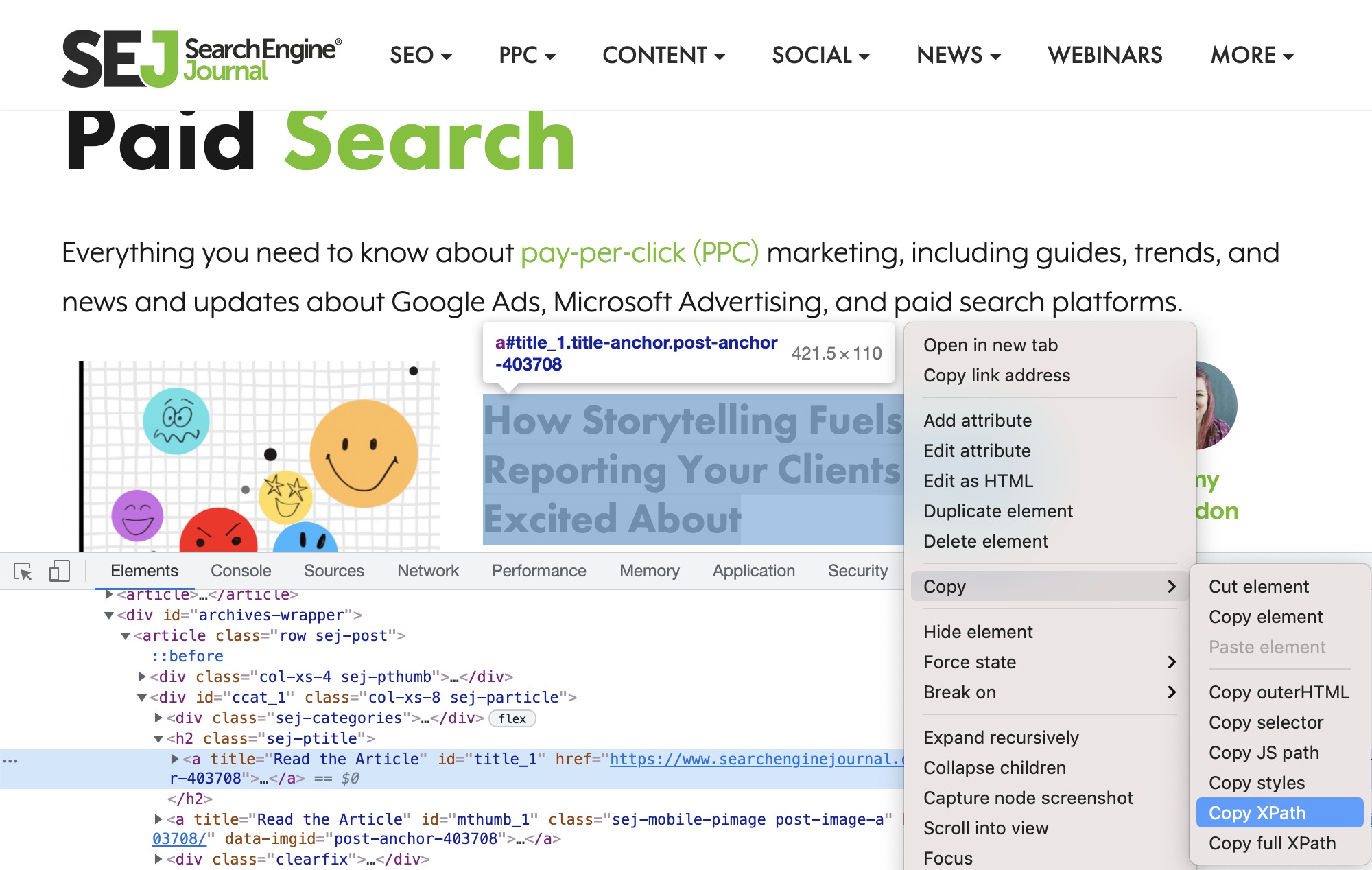
توجه إلى Chrome. بعد التمرير فوق عنوان إحدى المقالات ، انقر بزر الماوس الأيمن وحدد فحص.
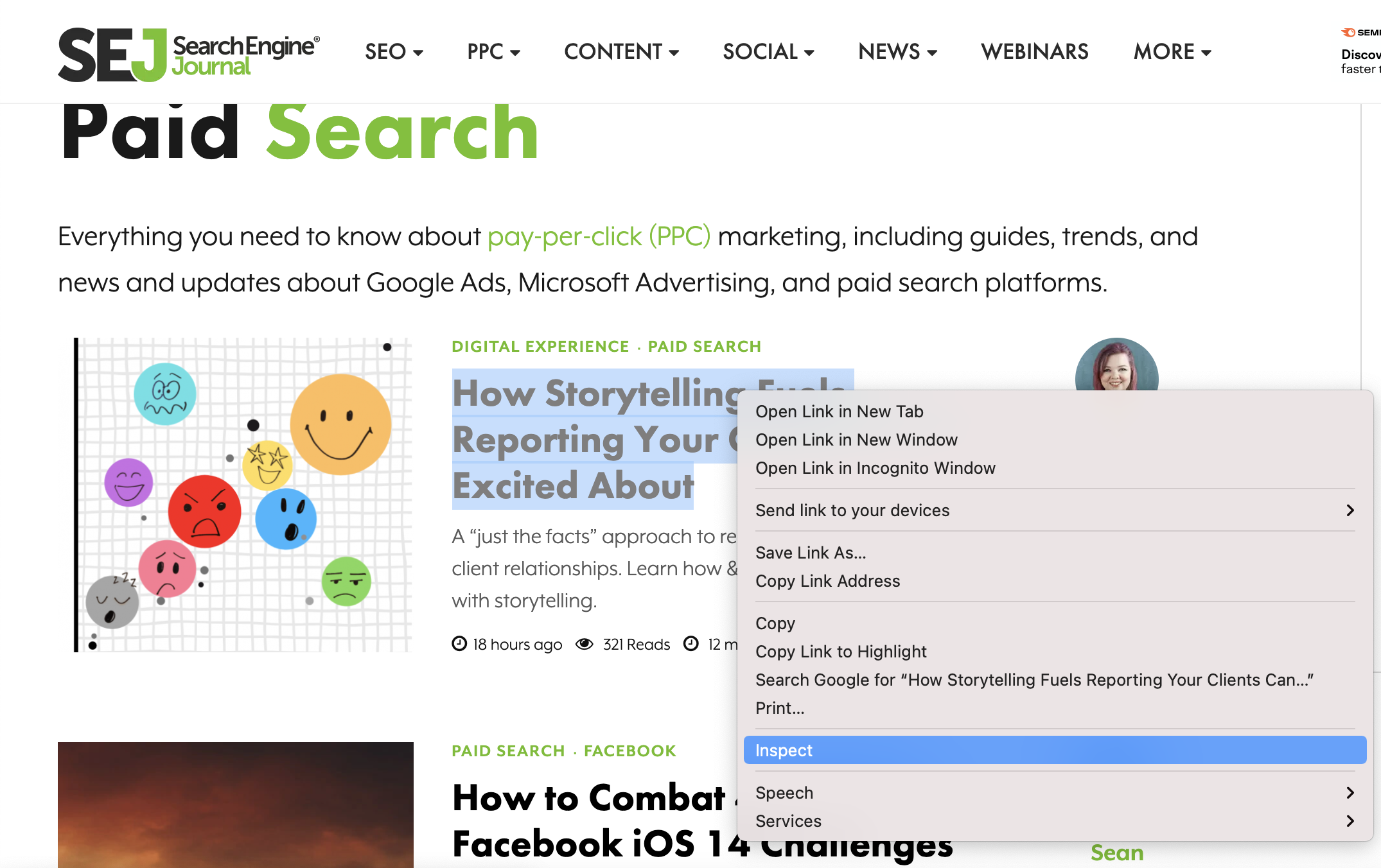 لقطة شاشة لموقع SearchEngineJournal.com ، يوليو 2021
لقطة شاشة لموقع SearchEngineJournal.com ، يوليو 2021سيؤدي هذا إلى فتح نافذة Chrome Dev Tools:
 لقطة شاشة لموقع SearchEngineJournal.com ، يوليو 2021
لقطة شاشة لموقع SearchEngineJournal.com ، يوليو 2021تأكد من استمرار تحديد عنوان المقالة وتمييزه ، ثم انقر بزر الماوس الأيمن مرة أخرى واختر نسخ> نسخ XPath.
دعاية
أكمل القراءة أدناه
الخطوة 4: استخرج البيانات إلى جداول بيانات Google
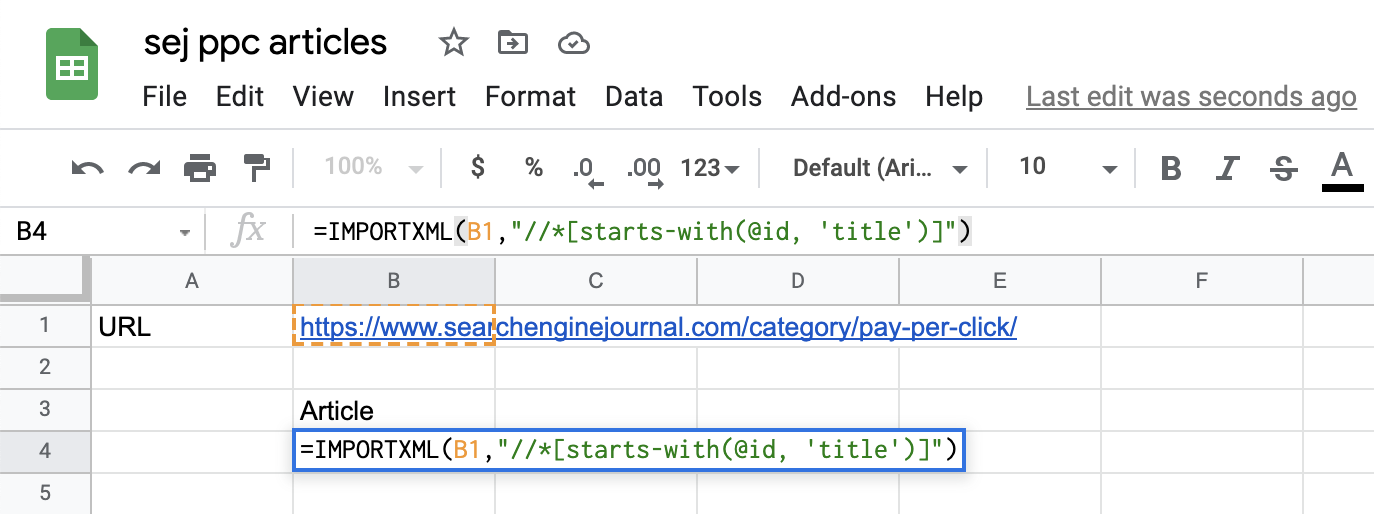
مرة أخرى في مستند Google Sheets الخاص بك ، قم بتقديم وظيفة IMPORTXML على النحو التالي:
= IMPORTXML (B1، “// *[starts-with(@id, ‘title’)]”)
بعض النقاط التي يجب ملاحظتها:
أولا، في صيغتنا ، استبدلنا عنوان URL للصفحة بمرجع إلى الخلية حيث يتم تخزين عنوان URL (B1).
الثانية، عند نسخ XPath من Chrome ، فسيكون دائمًا محاطًا بعلامات اقتباس مزدوجة.
(// *[@id=”title_1″])
ومع ذلك ، للتأكد من أن هذا لا يكسر الصيغة ، يجب استبدال علامة الاقتباس المزدوجة بعلامة الاقتباس المفردة.
(// *[@id=’title_1’])
لاحظ أنه في هذه الحالة ، نظرًا لأن عنوان معرف الصفحة يتغير لكل مقالة (العنوان_1 ، العنوان_2 ، إلخ) ، نحتاج إلى تعديل الاستعلام قليلاً واستخدام “يبدأ بـ” لالتقاط جميع العناصر في الصفحة باستخدام معرّف يحتوي على “العنوان”.
هذا هو الشكل الذي يبدو عليه في مستند “جداول بيانات Google”:
 لقطة شاشة من جداول بيانات Google ، يوليو 2021
لقطة شاشة من جداول بيانات Google ، يوليو 2021وفي لحظات قليلة ، هذا ما تبدو عليه النتائج بعد أن يقوم الاستعلام بتحميل البيانات في ورقة العمل:
 لقطة شاشة من جداول بيانات Google ، يوليو 2021
لقطة شاشة من جداول بيانات Google ، يوليو 2021كما ترى ، تعرض القائمة جميع المقالات التي كانت على الصفحة التي خدشناها للتو (بما في ذلك مقالتي السابقة عن الأتمتة وكيفية استخدامها أدوات تخصيص الإعلانات لتحسين أداء حملات إعلانات Google).
دعاية
أكمل القراءة أدناه
يمكنك أيضًا تطبيقه على استرداد أي معلومة أخرى مطلوبة لإعداد حملتك الإعلانية.
دعنا نضيف عناوين URL للصفحات المقصودة ، ملف مقتطف مميز من كل مقال ، واسم المؤلف في مستند “جداول البيانات” الخاص بنا.
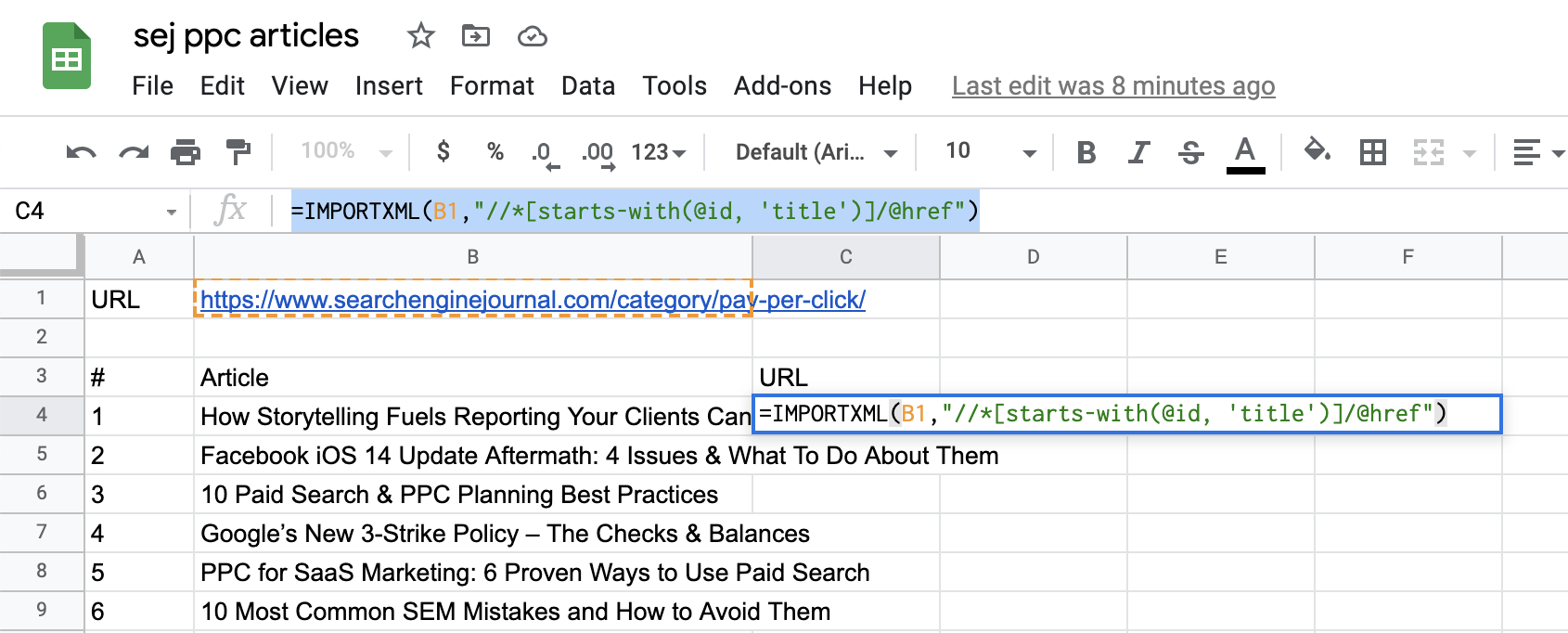
بالنسبة لعناوين URL للصفحة المقصودة ، نحتاج إلى تعديل الاستعلام لتحديد أننا بعد عنصر HREF المرفق بعنوان المقالة.
لذلك ، سيبدو استعلامنا كما يلي:
= IMPORTXML (B1، “// *[starts-with(@id, ‘title’)]/ @ href “)
أضف الآن “/ @ href” في نهاية Xpath.
 لقطة شاشة من جداول بيانات Google ، يوليو 2021
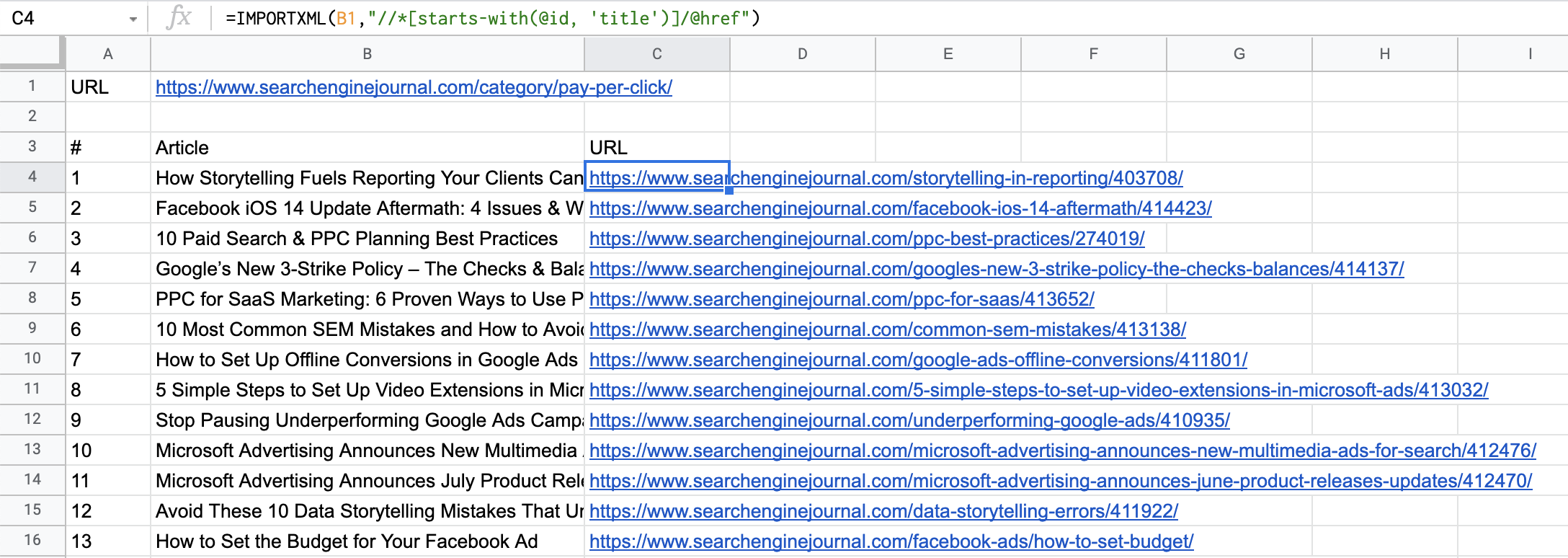
لقطة شاشة من جداول بيانات Google ، يوليو 2021لذا ! لدينا على الفور عناوين URL للصفحات المقصودة:
 لقطة شاشة من جداول بيانات Google ، يوليو 2021
لقطة شاشة من جداول بيانات Google ، يوليو 2021يمكنك أن تفعل الشيء نفسه مع المقتطفات المميزة وأسماء المؤلفين:
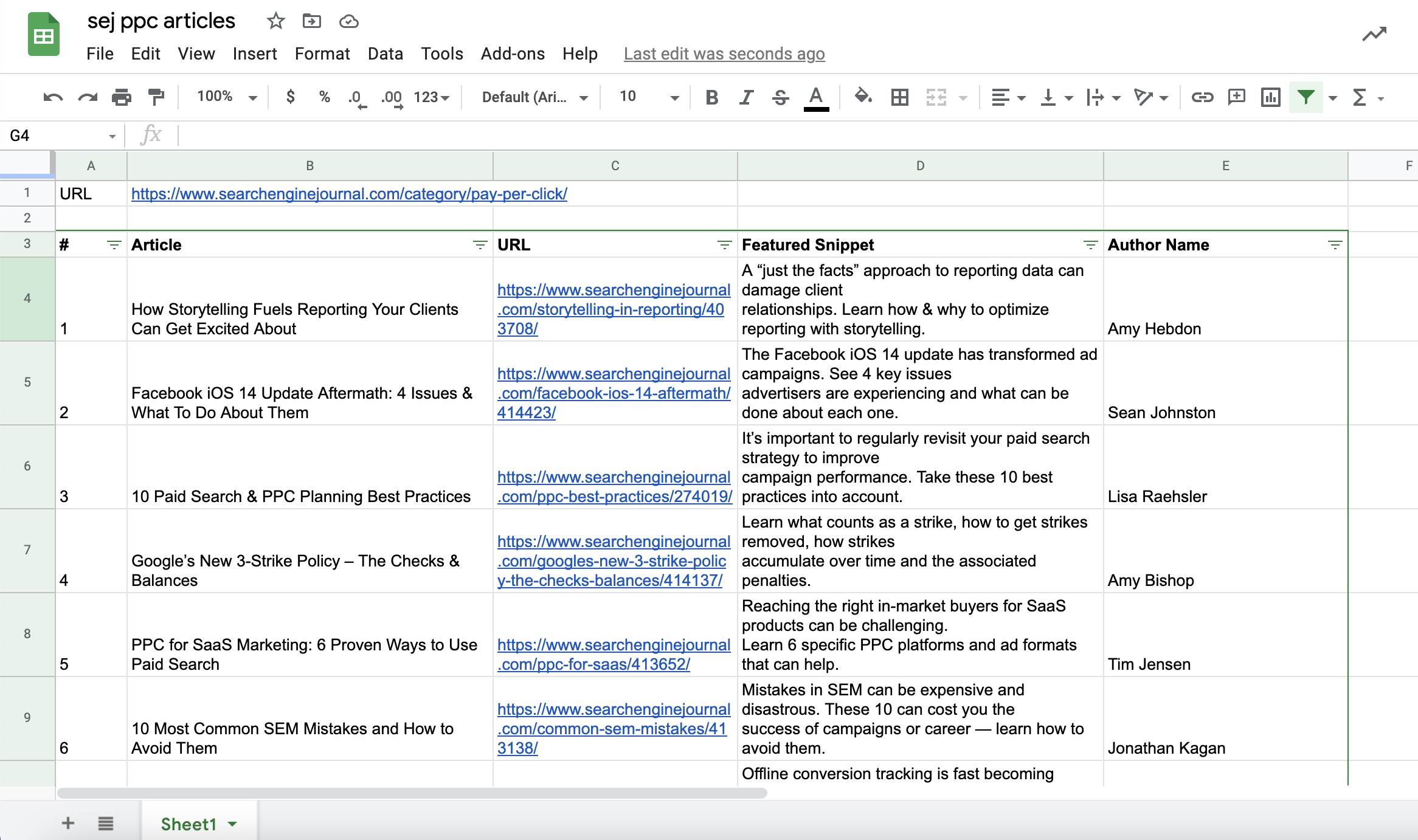 لقطة شاشة من جداول بيانات Google ، يوليو 2021
لقطة شاشة من جداول بيانات Google ، يوليو 2021بصلح
شيء واحد يجب أن تكون حذرًا منه هو أنه لكي تتمكن من توسيع ورقة العمل وملؤها بالكامل بجميع البيانات التي يتم إرجاعها بواسطة الاستعلام ، يجب أن يحتوي العمود الذي يتم ملء البيانات فيه على خلايا حرة كافية ولا توجد بيانات أخرى في المسار.
دعاية
أكمل القراءة أدناه
وهي تعمل بنفس الطريقة التي تعمل بها عندما نستخدم ARRAYFORMULA ، لكي تتسع الصيغة لا ينبغي أن تكون هناك بيانات أخرى في نفس العمود.
استنتاج
وهناك طريقة مؤتمتة بالكامل وخالية من الأخطاء لاسترداد البيانات من (من المحتمل) أي صفحة ويب ، سواء كنت بحاجة إلى المحتوى ووصف المنتج ، أو بيانات التجارة الإلكترونية مثل سعر المنتج أو تكاليف الشحن.
في عصر يمكن أن تكون فيه المعلومات والبيانات هي الميزة المطلوبة لتقديم نتائج أعلى من المتوسط ، يمكن أن تكون القدرة على كشط صفحات الويب والمحتوى المنظم بطريقة سريعة وسهلة لا تقدر بثمن. بالإضافة إلى ذلك ، كما رأينا أعلاه ، يمكن أن تساعد IMPORTXML في تقليل أوقات التنفيذ ومخاطر الأخطاء.
علاوة على ذلك ، فإن الوظيفة ليست فقط أداة رائعة يمكن استخدامها حصريًا مهام قدرة شرائية، ولكن يمكن أن تكون مفيدة جدًا في العديد من المشاريع المختلفة التي تتطلب تجريف الويب ، بما في ذلك تحسين محركات البحث ومهام المحتوى.
العد التنازلي لعيد الميلاد 2021 SEJ:
دعاية
أكمل القراءة أدناه
الصورة المميزة: أليوتي / شاترستوك
#كيفية #استخدام #جداول #بيانات #Google #لإنشاء #حملات #ويب #سكراتش
المصدر
تعليقات
إرسال تعليق